Split Learning
개요
Split Learning은 모델을 여러 장치 간에 분할하여 데이터가 로컬을 벗어나지 않으면서도 협업 학습이 가능하도록 하는 프라이버시 중심의 분산 학습 기술입니다. 본 글에서는 Split Learning의 개념, 구조, 주요 기술 요소, Federated Learning과의 비교, 보안성과 활용 사례를 중심으로 실무 도입 가능성을 살펴봅니다.
1. 개념 및 정의
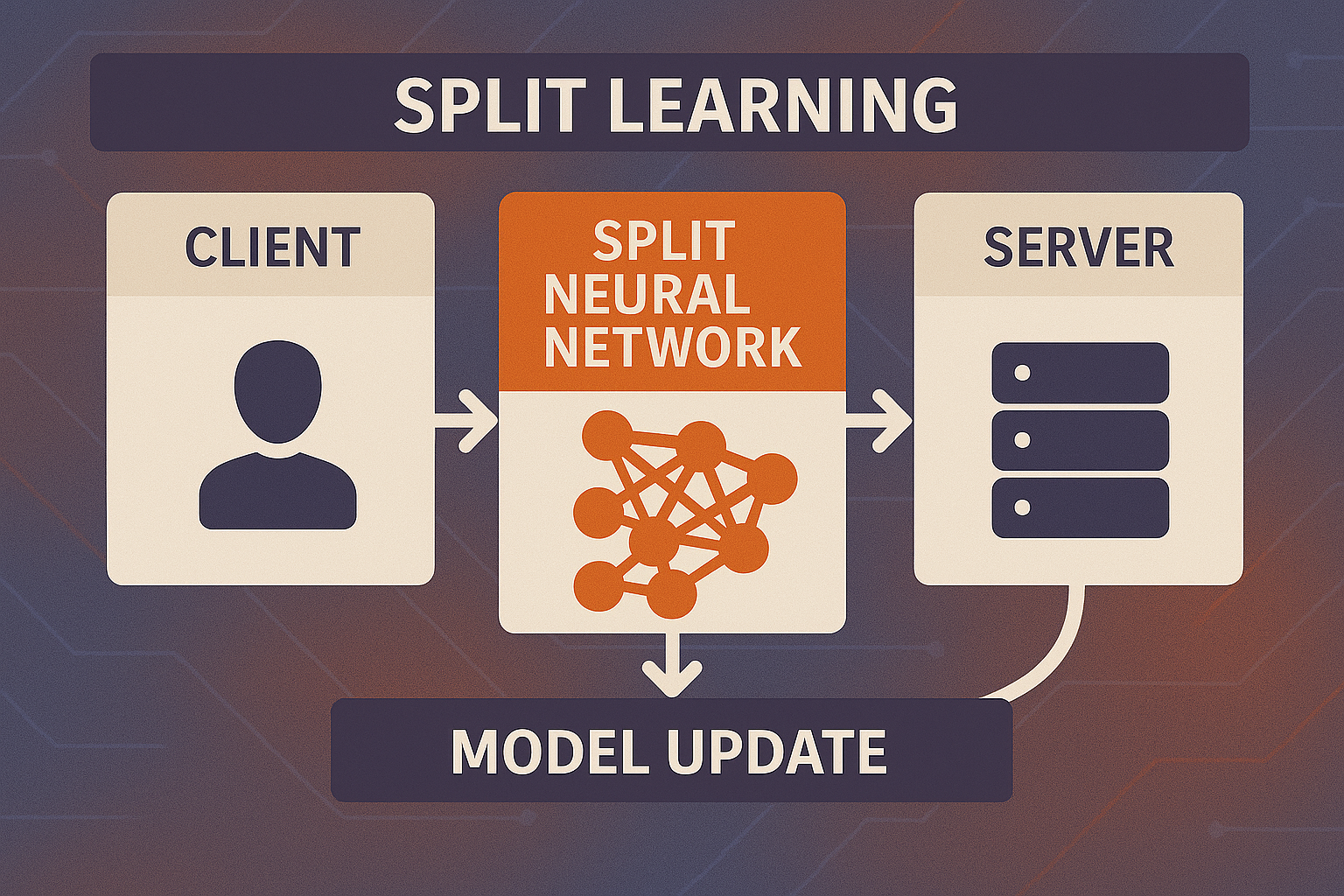
Split Learning은 딥러닝 모델을 클라이언트와 서버로 나누어 학습하는 방식으로, 클라이언트는 전방 레이어만 계산하고 서버는 후방 레이어를 계산합니다. 이 구조는 원본 데이터를 서버에 전송하지 않아도 되므로 프라이버시와 보안성이 크게 향상됩니다.
- 목적: 데이터 프라이버시 보호 및 연산 분산
- 기반 원리: 모델 분할 및 순방향/역방향 전파 분리
- 구조 형태: 단일 클라이언트-서버 / 다수 병렬 클라이언트 등 다양화 가능
2. 특징
| 항목 | 설명 | 장점 |
| 모델 분할 학습 | 전체 모델을 나누어 각자 계산 | 자원 효율적 협업 학습 가능 |
| 데이터 분리 유지 | 원본 데이터는 로컬에 유지 | 프라이버시 보장 |
| 통신 효율성 | 활성화 값만 전송 | 대역폭 부담 감소 |
Split Learning은 특히 의료, 금융 등 민감 데이터를 다루는 도메인에서 주목받고 있습니다.
3. 구성 요소
| 구성 요소 | 설명 | 역할 |
| 클라이언트 모델(front model) | 모델 전반부 레이어 | 로컬에서 입력 처리 및 활성화 계산 |
| 서버 모델(back model) | 모델 후반부 레이어 | 서버 측에서 나머지 학습 수행 |
| cut layer | 모델을 나누는 분할 지점 | 학습 효율성과 보안성 트레이드오프 중심 |
각 장치는 자신의 모델 일부만을 소유하며, 학습 시 forward/backward 정보를 교환합니다.
4. 기술 요소
| 기술 요소 | 설명 | 적용 방식 |
| SplitNN | 분할 신경망 구조의 일반 모델 | PyTorch/TensorFlow로 구현 가능 |
| Gradients Exchange | 역전파 시 클라이언트-서버 간 그래디언트 교환 | 비동기식 학습도 가능 |
| Partial Model Aggregation | 클라이언트 단 분산 처리 가능 | 서버 연산 부담 경감 |
Split Learning은 Federated Learning보다 더 세분화된 모델 제어가 가능하다는 점에서 차별화됩니다.
5. 장점 및 이점
| 장점 | 설명 | 효과 |
| 프라이버시 강화 | 원본 데이터 이동 없음 | 민감 정보 노출 방지 |
| 자원 분산 | 연산 및 저장소 분산 가능 | 클라이언트 부담 최소화 |
| 다양한 구조 확장 | VFL, HFL, 동형암호와 병행 가능 | 확장성 및 보안성 동시 확보 |
Split Learning은 다양한 딥러닝 구조와 통합할 수 있어, 맞춤형 AI 협업 모델 구성에 유리합니다.
6. 주요 활용 사례 및 고려사항
| 분야 | 활용 사례 | 고려사항 |
| 의료 AI | 병원 간 공동 질병 예측 모델 학습 | 네트워크 안정성, 동기화 필요 |
| 금융 | 고객 거래 정보 기반 협업 모델 | 규제 준수 및 보안 감사 필요 |
| 스마트 제조 | 장비 센서 데이터로 이상 탐지 모델 | 실시간성 vs 보안성 조율 필요 |
도입 전, 클라이언트 간 계산 능력 차이, 통신 병목, 데이터 정렬 방식에 대한 설계가 선행되어야 합니다.
7. 결론
Split Learning은 데이터 공유 없이 고성능 AI 학습이 가능한 구조로, 민감 정보 보호와 협업 학습이라는 두 가지 요구를 동시에 만족시킵니다. 특히 의료·금융 등 규제가 엄격한 산업에서 활용 가치가 높으며, Federated Learning의 한계를 보완하는 대안 또는 병행 구조로 각광받고 있습니다. 앞으로 실시간성과 보안이 동시에 요구되는 AI 서비스에서 중요한 학습 전략이 될 것입니다.