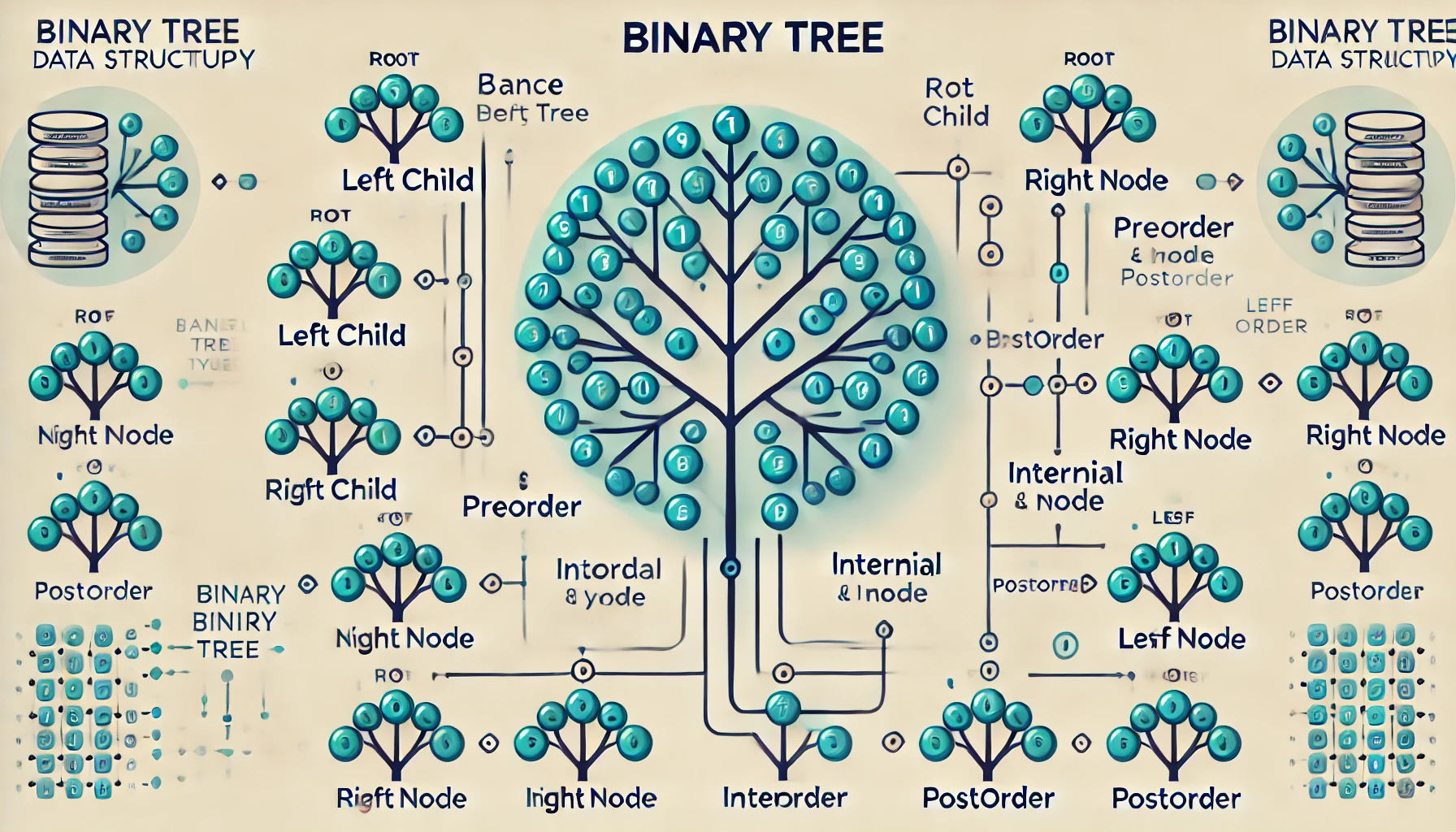
개요이진 탐색 트리(BST, Binary Search Tree)는 이진 트리의 일종으로, 왼쪽 서브트리에는 루트보다 작은 값이, 오른쪽 서브트리에는 루트보다 큰 값이 저장되는 자료구조이다. 중복 없는 정렬된 데이터를 저장하면서 빠르게 탐색, 삽입, 삭제가 가능하며, 평균적으로 O(log n)의 성능을 보인다. 알고리즘 문제풀이와 데이터베이스, 메모리 관리 등 다양한 분야에 활용된다.1. BST의 구조와 특징 구성 요소 설명 루트(Root)트리의 최상위 노드노드(Node)데이터와 자식 포인터를 포함한 단위왼쪽 자식루트보다 작은 값오른쪽 자식루트보다 큰 값BST는 모든 노드에 대해 왼쪽 이 성립한다.2. BST의 연산 동작 원리연산동작 방식시간 복잡도 (평균/최악)탐색(Search)루트부터 값 비교, 작으..