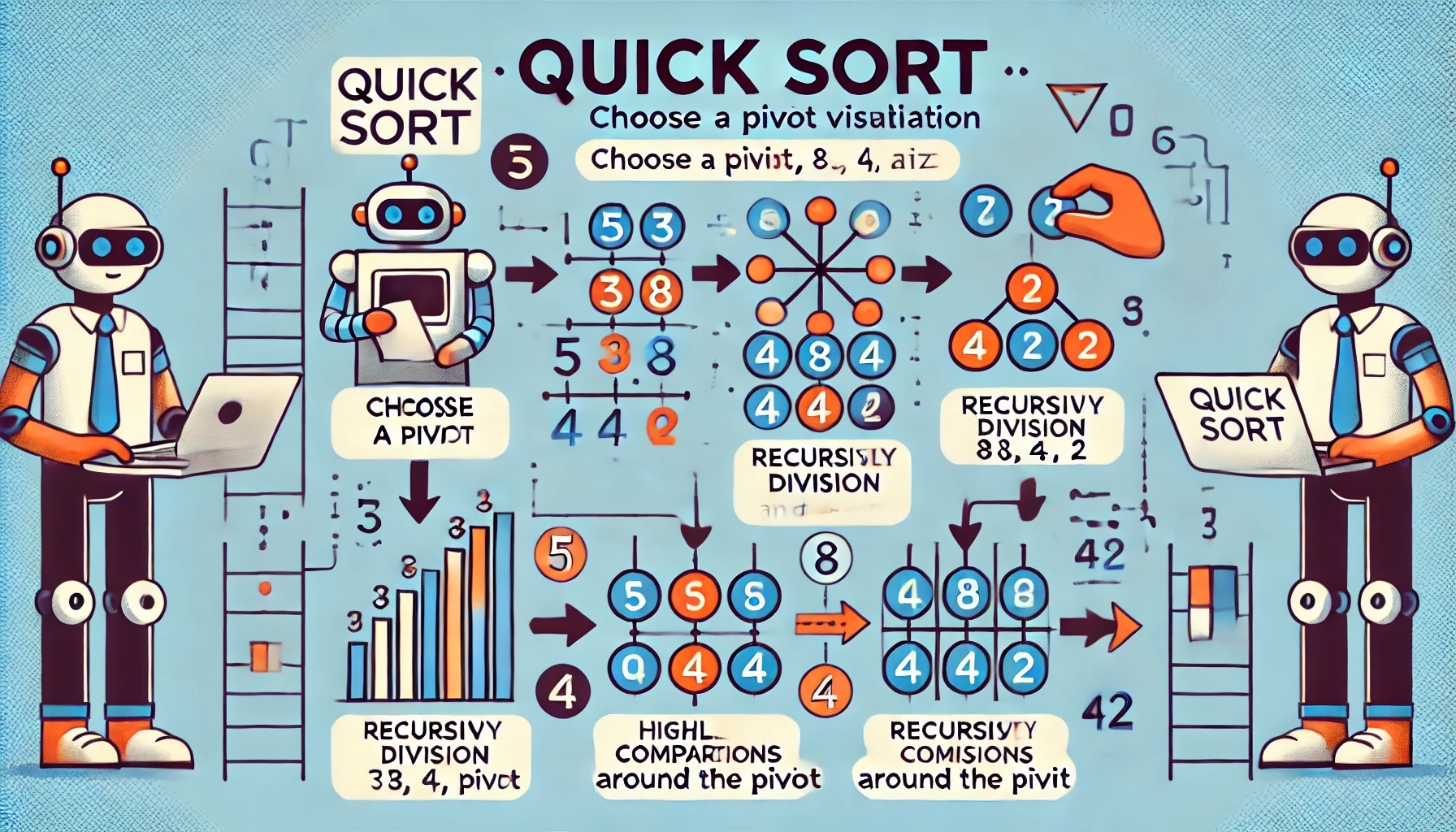
개요분할 정복(Divide and Conquer)은 큰 문제를 작고 동일한 구조의 하위 문제로 나눈 뒤, 이를 각각 해결하고 결합하여 전체 문제를 해결하는 알고리즘 전략이다. 컴퓨터 과학에서 가장 널리 사용되는 알고리즘 설계 패러다임 중 하나로, 정렬, 탐색, 수학 계산, 동적 프로그래밍 등 다양한 분야에 활용된다. 병렬 처리와 최적화 문제에도 효과적이다.1. 개념 및 정의분할 정복은 다음과 같은 3단계로 구성된다:Divide (분할): 문제를 동일한 구조의 더 작은 하위 문제로 나눈다.Conquer (정복): 각 하위 문제를 재귀적으로 해결한다.Combine (결합): 하위 문제의 해를 결합하여 원래 문제의 해를 도출한다.2. 대표 알고리즘 예시 알고리즘 설명 시간 복잡도 병합 정렬 (Merge S..